 Don't worry. Think, and do.
Don't worry. Think, and do.
Music Information Retrieval Notes
Per my friend’s interest on the application of deep learning on music, I decided to try some state-of-the-art in the area of Music Information Retrieval.
- Music recommendation system of Spotify
- Music Genre Recognition by DeepSound
- Music recommendation by Keunwoo Choi
- Example 5-2
- Other public repos
- Research papers
Music recommendation system of Spotify
The starting point of this journal is this blog: Spotify’s Discover Weekly: How machine learning finds your new music.
The basic idea of the deep learning stuff in this article is: just as the feature extracted by CNN contains important information for an image, if we can extract information with a music classification model, we can use it to recommend information.
In particular, the blog referred to Recommending music on Spotify with deep learning, a project in 2014 by Sander Dieleman, an intern at Spotify, who is now at DeepMind.
Interestingly, the model is CNN and the analysis is conducted on segments of music. Actually, the task of music classification (which is usually referred to as Music Genre Recognition instead) generally use CV models on video such as CNN or CRNN.
Music Genre Recognition by DeepSound
Since Sander was unable to share his code, I go on to Music Genre Recognition by Piotr Kozakowski & Bartosz Michalak from DeepSound in 2016 implementing the paper Deep Image Features in Music Information Retrieval in 2014.
The cool part of this project is that not only did they share their codes but they also have a great front end to showcase (Demo).
They also shared the front end so it is possible to download and try the music analysis on your own piece of music. The model is CRNN in Keras and capable of Live Music Genre Recognition.
One way to interpret how CNN works in music is to make an analogy of the 2D-conv in music classification to the 3D-conv in video classification, where the second axis of the convolutional kernel exploits the temporal structure of a piece of music.
And therefore, as an effective way to aggregate global temporal information, an RNN model built on top of the local CNN might help to classify the whole music.
Run their code
I opened a new environment in my anaconda and installed the requirement. I found out that they were using Python 2.7 indeed and changed the python version of my environment.
When I ran, it told me that I did not install TensorFlow. I opened the requirements.txt and there was no TensorFlow in it.
So I pip install tensorflow, but this time it said
x = tf.python.control_flow_ops.cond(tf.cast(_LEARNING_PHASE, 'bool'),
AttributeError: 'module' object has no attribute 'python'
Probably as this issue explained, I had the wrong version of TensorFlow installed.
The version of Keras they used was 1.1.0 so the version of TensorFlow was probably very dated. The oldest one available for pip install was 0.12.0. I reinstalled to that version but still not working.
However, the error changed to
x = tf.python.control_flow_ops.cond(tf.cast(_LEARNING_PHASE, 'bool'),
AttributeError: 'module' object has no attribute 'control_flow_ops'
This time I found out that I need to install TensorFlow version 0.10, but it is not available through direct pip install.
So I went to TensorFlow 0.10 on GitHub and followed the pip installation instruction:
# Mac OS X, CPU only, Python 2.7:
$ export TF_BINARY_URL=https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-0.10.0-py2-none-any.whl
# Mac OS X, GPU enabled, Python 2.7:
# $ export TF_BINARY_URL=https://storage.googleapis.com/tensorflow/mac/gpu/tensorflow-0.10.0-py2-none-any.whl
# Python 2
$ sudo pip install --upgrade $TF_BINARY_URL
I want to show it to my friend with my MacBook so I set up the environment on my laptop.
I was blocked by GFW for the last step, so I went to the cafeteria and used IPv6 instead (sigh).
Then the last bug said
assert type(outputs) in {list, tuple}, 'Output to a TensorFlow backend function should be a list or tuple.'
AssertionError: Output to a TensorFlow backend function should be a list or tuple.
I checked the code and in common.py, I modified one line of get_layer_output_function function to
f = K.function([input, K.learning_phase()], (output, ))
then it works. (probably it is because the TensorFlow version is still not correct? Maybe the simplest solution is to ask them for their version name)
Run with GPU
Indeed CPU was unbearably slow, so I decided to try with GPU, but I failed to achieve that. The error message was:
File "/home/hanezu/anaconda/envs/deepsound-genre-recog/lib/python2.7/site-packages/tensorflow/python/pywrap_tensorflow.py", line 24, in swig_import_helper
_mod = imp.load_module('_pywrap_tensorflow', fp, pathname, description)
ImportError: libcudart.so.7.5: cannot open shared object file: No such file or directory
It seems that Tensorflow 0.10 cannot run on my cuda 8.0. But mixing cuda 7.5 and 8.0 seems to be such a pain that I gave up. (Hoping there will be a CUDA environment manager like Anaconda!)
From this attempt I was frustrated with the quick update and backward inconsistency of deep learning platform such as TensorFlow. Probably I would better try some new project.
Music recommendation by Keunwoo Choi
Keunwoo Choi worked from several approaches, including
- Combining shallow and deep features from CNN to assemble a general-purposed feature for transfer learning
- Tagging using CNN or CRNN
- A tutorial on Deep Learning for Music Information Retrieval
Transfer learning
Transfer learning for music classification and regression tasks (Code) used concatenated features from different layers so that the extracted feature can be later on used in various tasks.
Remark
If I correctly interpreted the paper, the definition of “Transfer learning” here has a subtle difference from its original meaning.
- Original: pretrain a model for one task, and finetune it for other tasks.
- Here: train a model for a task and use it as feature extractor for other tasks.
i.e., while the parameters of the model are generally modified when applied to other tasks, here the model’s parameters are fixed.
Instead, the author suggested an inspiring idea that different tasks tend to emphasize on the parts of features coming from different layers.
 The 6 tasks to tackle
The 6 tasks to tackle
Music Tagging
Another work is on Music Tagging (arXiv: CONVOLUTIONAL RECURRENT NEURAL NETWORKS FOR MUSIC CLASSIFICATION) in Jan ‘17, a little bit earlier than his work for Transfer Learning. It reminded me of I2V.
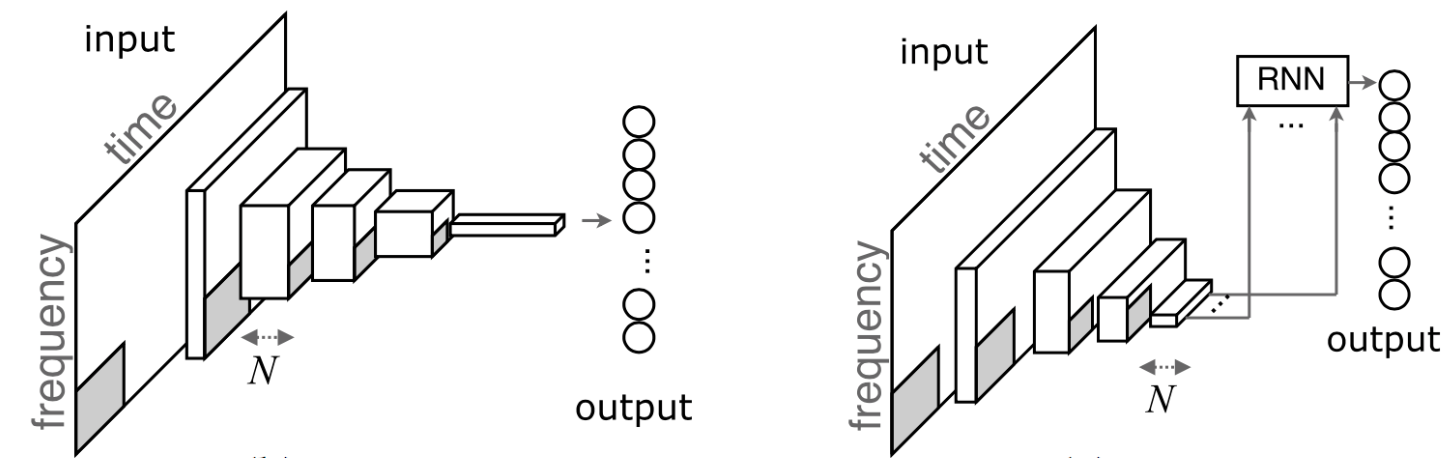 Left: compact_cnn, music_tager_cnn. Right: music_tagger_crnn
Left: compact_cnn, music_tager_cnn. Right: music_tagger_crnn
The music_tagger_crnn model is similar to the work of DeepSound, but predicting tags instead.
The author suggests compact_cnn over music_tager_cnn and music_tagger_crn since the latter ones are his old works.
Tensorflow Implementation
While K Choi used Theano, I also found a Tensorflow Implementation of this work. But they are both Keras anyway.
Kapre
Keunwoo Choi wrote a package for on-the-fly calculation of STFT/melspectrograms called kapre (Keras Audio Preprocessors).
Tutorial: DL4MIR
Keunwoo Choi also provided a tutorial for his tutorial paper: A Tutorial on Deep Learning for Music Information Retrieval. Amazing.
Below is how I walked through this tutorial.
Example 1 and 2
The first two examples was quick, although I was tripped by the error saying that the DataGen was not an Iterable.
It was because I used Python 3 (since he used print with surrounding parentheses!), but indeed it was Python 2. The difference is that in Python 2 the iterable has the next() method, while in Python 3 it becomes the __next__() method.
To be secure, I switched to Python 2.
Example 5-1: is there anyone singing?
In this example, we identify whether the singer was singing at a specific time of an audio.
To achieve this, we train an RNN to, at any time in an audio, classify Here, from the homepage of Jamendo:
- sing: segments containing singing voice or spoken voice (generally over an instrumental background)
- nosing: pure instrumental (or silence) segments with no voice.
It was wierd that datasets in Kapre package seems to have forgot import os and raised NameError: name 'os' is not defined.
I solved it by cd ~/anaconda/envs/dl4mir/lib/python2.7/site-packages/kapre-0.1.2.1-py2.7.egg/kapre and added import os to datasets.py.
Then librosa.load raised NoBackendError and I followed macramole’s comment and sudo apt-get install libav-tools.
Then Keras needs to have h5py installed when saving models .
I tried to pip install h5py but it returned Requirement already satisfied: h5py in /home/hanezu/anaconda/lib/python3.6/site-packages, although I was activated in a python2.7 environment! Solved by conda install h5py.
Update: in fact I made a stupid mistake. I did not deactivate and re-activate my environment after I changed the python version. The result was that whatever I tried to pip install, the pip would install package for the former python version.
after 30 epochs each, the training result was
| Model | Accuracy |
|---|---|
| CRNN | 75% |
| LSTM | 78% |
| bi-LSTM | 80% |
Let’s pick a song from the test dataset and see the performance of the bi-directional LSTM.
 The bi-LSTM classification result on sing and nosing, compared with ground truth.
The bi-LSTM classification result on sing and nosing, compared with ground truth.
As can be seen from the above figure, bi-LSTM did a better job than the percentage of accuracy suggested. (MFCCs baseline is 91.7% and SOTA convnet can achieve 97.2%)
Two side notes on the plot:
-
to find the audio (identified by a filename), I need to find out the corresponding preprocessed data (indexed by integers). The original codes used
os.listdirto get the list of audios and preprocessed in this order. However, this order cannot be relied upon and is an artifact of the filesystem., so a better choice is to usesorted(os.listdir(path))whenever the number of files is small. -
let’s double check that the audio is indeed correspond to the plot. The default sampling rate
SRis 16000 times/sec. Each model outputs a classification result everyN_HOP = 256samples. During training and validation, model takes a random 10-second slice of an audio as input, and output a list of length10 * 16000 / 256 = 625of binary classification posterior. During testing, it takes as many samples as it can, as long as the number of samples is a multiple ofN_HOP. Therefore for the above example, I used18310 outputs = 4687360 samples / N_HOP = 4:53 * SR
It was a bit slow since I did not enable GPU. However, later I installed GPU-version of TensorFlow following the instruction on the homepage, but it did not speed up much (GPU memory was used up but utility hardly went over 40%).
Example 5-2
after 5 epochs each, the training result was
| Model | Accuracy |
|---|---|
| multi_kernel | 38% |
| CRNN | 39% |
| CNN3x3 | 34% |
| CNN1D | 30% |
The models must be underfitting. Let’s train it with 100 epochs.
| Model | Accuracy | Epoch | Accuracy’ | Epoch’ |
|---|---|---|---|---|
| multi_kernel | 47% | 17 | 47.1% | 72 |
| CRNN | 44% | 13 | 45.6% | 65 |
| CNN3x3 | 42% | 21 | 44.7% | 83 |
| CNN1D | 25% | 8 | 40.4% | 89 |
By default, keras.callbacks.EarlyStopping(patience=5) triggered early stop when validation loss has plateaued for 5 epochs. Since the default setting stopped any model in 20 epochs, I configured the patience to be 50 epochs, corresponding to the column of Accuracy’ and Epoch’.
Although I did not finda a SoTA accuracy on fma_small dataset, since it is a 8,000 tracks of 30s, 8 balanced genres (GTZAN-like), I searched the GTZAN SoTA accuracy, which is 94.5%, and MFCCs baseline is 66.0%.
It is interesting to note that the baseline model CNN1D (corresponding to CNN with 2D-conv in video classification) was able to reach 40.4% after patient training. It means that the attempt to make use of temporal information does not beat an average of posterior of classification over the discrete spectrogram by a large margin.
It might be the case for video since you can probably guess the class of the video by just a snapshot, but not so natural when it comes to music. It seems to be a hard task to recognize the genre by a single chord or harmony, without temporal information such as tempo or key (well it is possible to guess the key from the chord).
Other public repos
Deep Audio Classification
A project by despoisj in TensorFlow (and his blog).
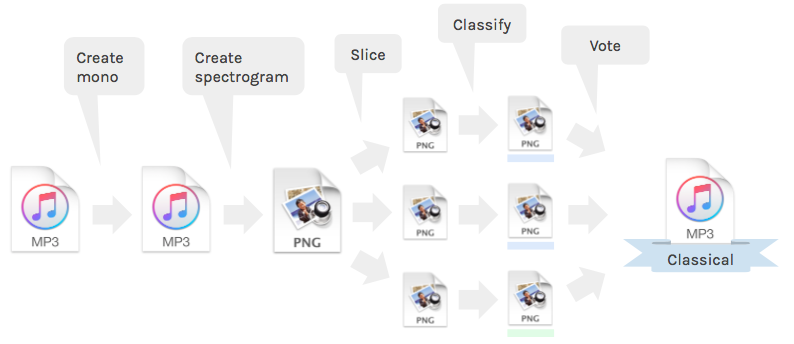
This implementation plainly used CNN to classify slices of the spectrogram of a piece of music and combine the results into the class of the music.
It is possible to train this model with your personal music library, just by placing the mp3 files in the data path and run the code.
It seems that I can also predict the class of a new piece of music (although unable to manipulate the genre information in the mp3 files though) without writing additional codes.
However, no pretrained model nor data is provided (Despoisj used his own iTunes library).
MusicGenreClassification
A project by mlachmish in TensorFlow that almost implemented Sander Dieleman’s blog.
Research papers
The table version of Deep Learning for Music (DL4M) is an up-to-date summary of papers.
End-to-end learning for music audio tagging at scale
End-to-end learning for music audio tagging at scale (with paper and demo) is another work on music tagging.
They claimed to use 1.2 million tracks of supervised data for this task, but seems not to be public right now.
Interestingly, they used domain knowledge and separated timbral (the quality of a sound independent of its pitch and volume) features from temporal features.
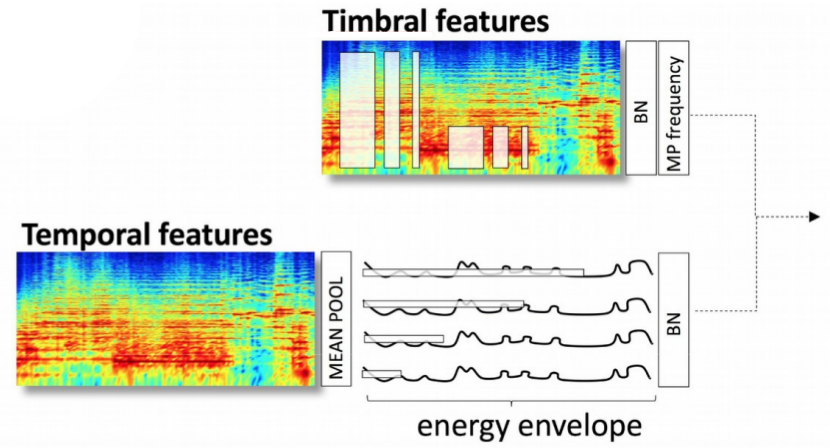 Separating timbral features and temporal features
Separating timbral features and temporal features
The above is the spectrogram front-end they used. As a contrast, waveform front-end is a conventional plain CNN. Both of them are followed with a same plain CNN as back-end.
An interesting detail is that on P3 of the paper, they noted
We optimize MSE instead of cross-entropy because part of our target tags (annotations) are not bi-modal.
This is an interesting idea when we work on the task of music audio tagging, since the tags of music are generally not bi-modal. For example, on their demo, tags such as “joyful lyrics” or “danceable” can be interpreted as non-bi-modal tags, and the human tags can be either a score number itself, or can be an average of bi-modal judgment.
Therefore, as a regression problem, MSE is the right loss to choose. However, using a conbination of cross-entropy on bi-modal tags and MSE on non-bi-modal tags may be a better choice.
Non-local Neural Networks
A new work on video classification, Non-local Neural Networks by Xiaolong Wang suggested an approach to exploit the temporal structure of the data by adding non-local blocks after some convolutional layers in plain CNN so that the local model can now put attention on some related information even across large time-space gap.
Recently there emerged a trend of using feedforward (i.e., non-recurrent) networks for modeling sequences in speech and language, e.g., WaveNet and Seq2Seq. X Wang demonstrated the effectiveness of CNN on music classification, which I doubted from the beginning of my research on music classification.
So feedforward approach might be an appropriate first step into the task of music classification, and adding non-local blocks might both enhance and simplify the feedforward model.
Written on November 21st , 2017 by Hanezu